天津大学端到端规划算法开源!自主飞行不再卡顿/附复现视频
在复杂障碍环境中实现无人机的自主飞行,一直是空中机器人领域的核心挑战之一。传统方案往往依赖地图构建和多阶段规划流程,存在延迟高、鲁棒性差等问题。天津大学电气自动化与信息工程学院卢俊杰等人在《IEEE Robotics and Automation Letters》发表论文“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning”,提出端到端规划算法YOPO。该方法无需实时建图,将感知、搜索与优化融为一体,一次前向推理即可生成安全轨迹;配合全新的Guidance Learning训练策略,YOPO在仿真与实机测试中实现毫秒级响应。
视频来源:https://www.youtube.com/watch\?v=m7u1MYIuIn4
01 研究背景
空中导航任务通常需要完成三大模块:感知建图、路径搜索、轨迹优化;这一传统“三段式”流程虽然结构清晰,但在实际部署中容易带来累计延迟高、误差易放大、重规划频率受限等瓶颈,尤其是在面对障碍密集环境的高速飞行任务时。针对这些问题,YOPO将深度感知、运动基元搜索与轨迹优化封装进同一网络,省去在线建图与串行调用,仅靠一次前向推理即可并行生成安全轨迹,实现毫秒级自主飞行。
02 系统介绍
该系统将“感知-规划-控制”链路整合为同一框架:
训练阶段,网络输入深度图、机体速度/加速度与目标方向;真值ESDF与位姿只是用来计算轨迹成本(平滑度、安全、目标)并生成数值梯度,通过Guidance Learning反向更新权重。视场内均匀布置的预定义运动基元作为锚点,网络预测其端点偏移和末端导数,进而得到多条候选轨迹并评估成本。
推理阶段,无需在线建图,将深度图、速度以及加速度特征输入模型,模型输出为所有预定义运动基元的偏移量,然后根据偏移量求解五次时间多项系数。实时生成可跟踪轨迹并交由控制器执行,实现毫秒级、无地图的自主飞行。
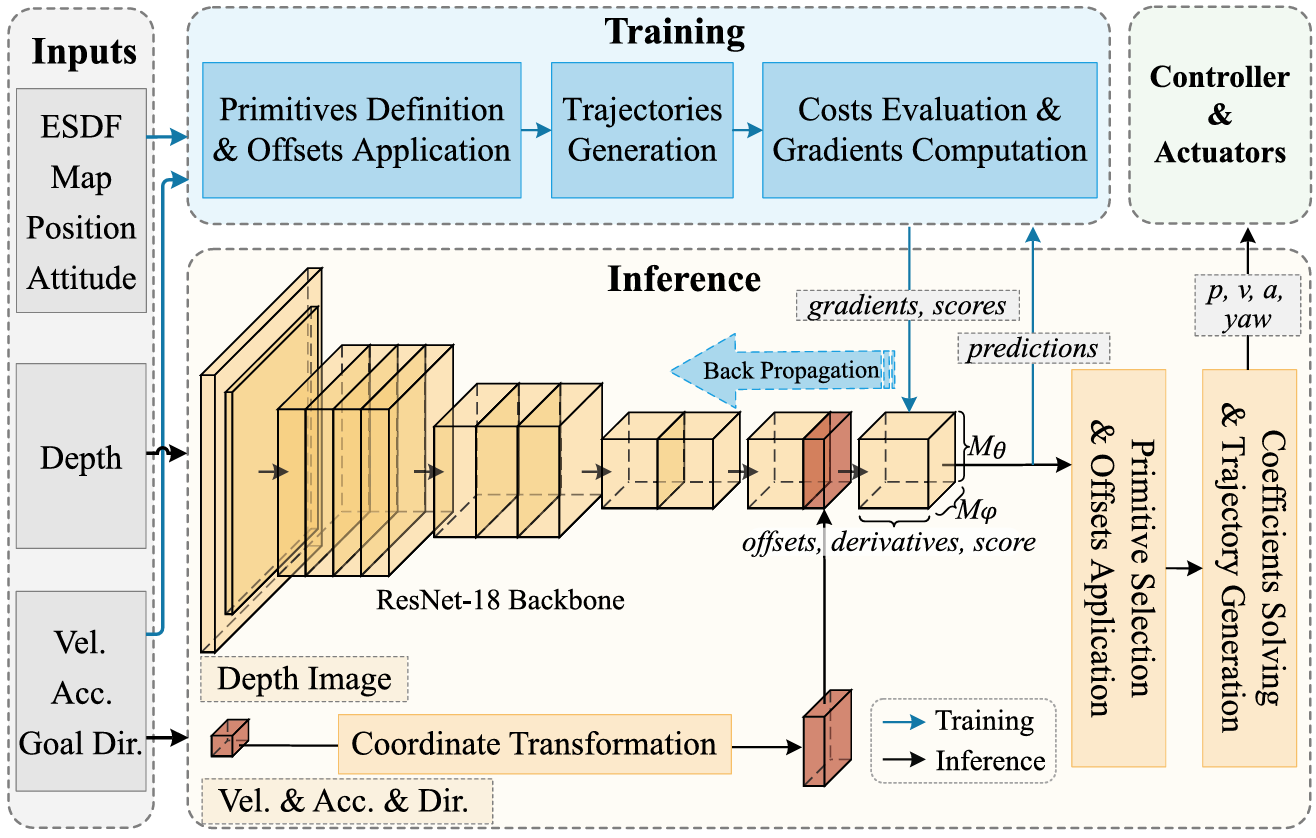
图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
03 技术亮点
一体化端到端规划框架
将感知、路径搜索与轨迹优化三个传统模块整合为单一神经网络结构,显著降低整体延迟。
模型以深度图、当前状态和目标方向为输入,一次前向传播即可输出多组候选轨迹参数(偏移量、末端导数与得分),实现快速决策。
运动基元+偏移预测机制
借鉴YOLO思想,采用固定运动基元(motion primitives)作为锚点,网络输出其偏移与得分以修正轨迹。
每个基元覆盖深度图中一个角度区域,并行预测所有基元的偏移、导数和得分,高效生成多样化局部轨迹,全面探索解空间。
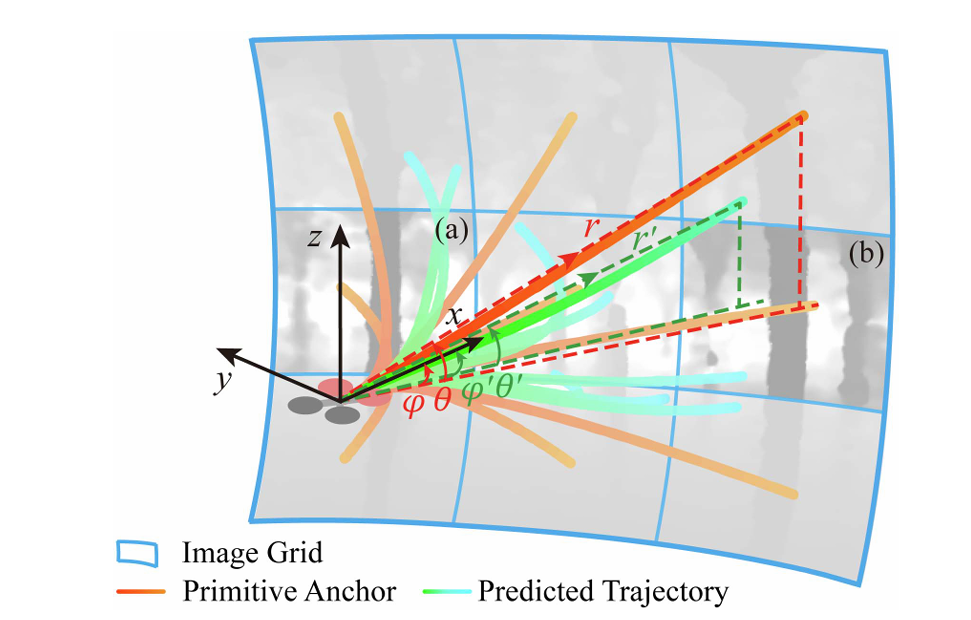
图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
引导学习(Guidance Learning)
利用环境的真实信息(如 ESDF 地图)计算数值梯度,直接用于训练网络参数,避免依赖专家示范。
该策略相比imitation learning更真实,且比 reinforcement learning更稳定高效,是一种无监督但具真实反馈的训练方法。
在训练中支持数据增强与多目标初始化,提升泛化能力且不需额外标签重注释。
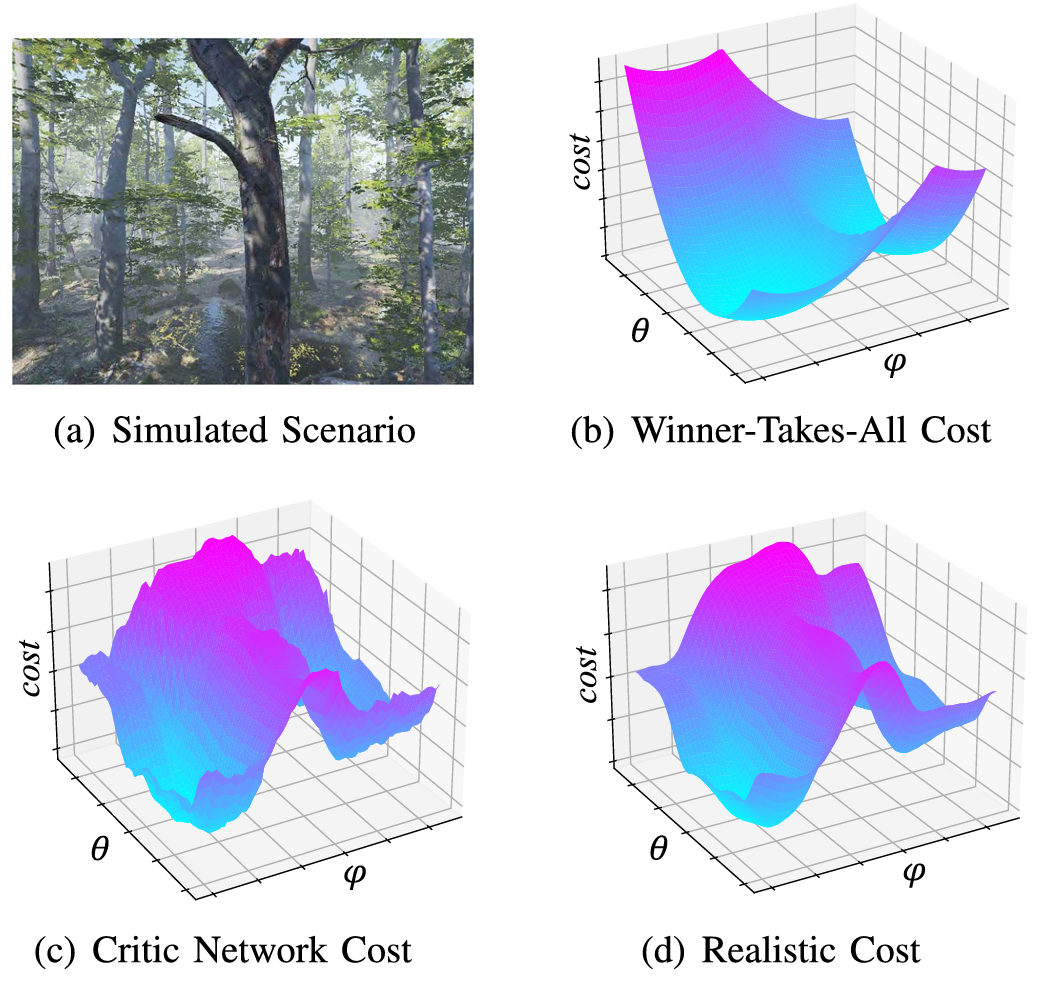
图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
特权学习(Privileged Learning)
在训练阶段引入特权信息(真实地图与完整状态)以获得更准确的梯度反馈;而在推理阶段仅依赖噪声深度图与低级状态信息。
提升模型对感知噪声的鲁棒性,在无地图、实时性要求高的任务中展现出较强性能。

图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
04 实验测试
对比试验
为验证所提出的Guidance Learning训练方法的有效性,研发团队将其与经典梯度优化方法进行对比。结果显示,Guidance Learning不仅平均规划代价更低,还能在更短时间内(1.6 ms)并行生成多条可行轨迹,具备更强的全局感知能力与鲁棒性。同时,在仿真密林环境中,YOPO相较于TopoTraj、MPPI和 Agile Autonomy,在延迟、安全性和成功率等指标上综合表现最优。
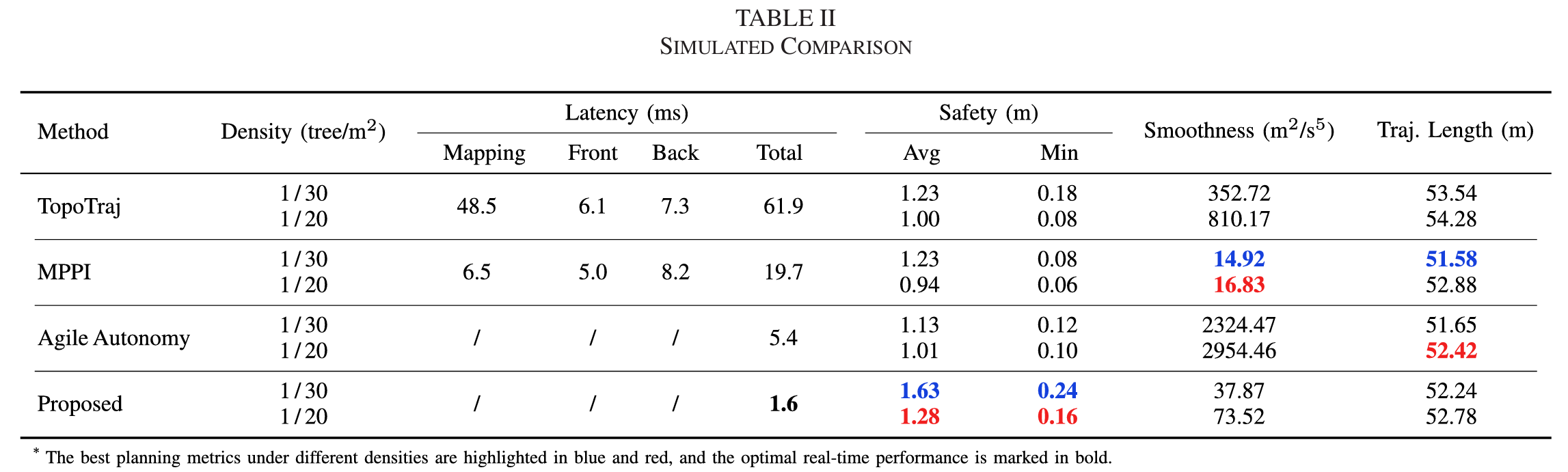
表格来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
真机实验
平台配置: 250mm轴距四旋翼,核心计算单元为NVIDIA Xavier NX,搭载RealSense D455深度相机,系统使用VINS-Fusion进行状态估计。

图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
飞行场景:树木密度大概为0.1 棵树/每平方米,真实环境未用于训练。测试结果:
最快飞行速度达5.52m/s;
能在突发障碍环境下快速重规划;
全程无需构建显式地图,展现了出色的实时性与环境适应能力。
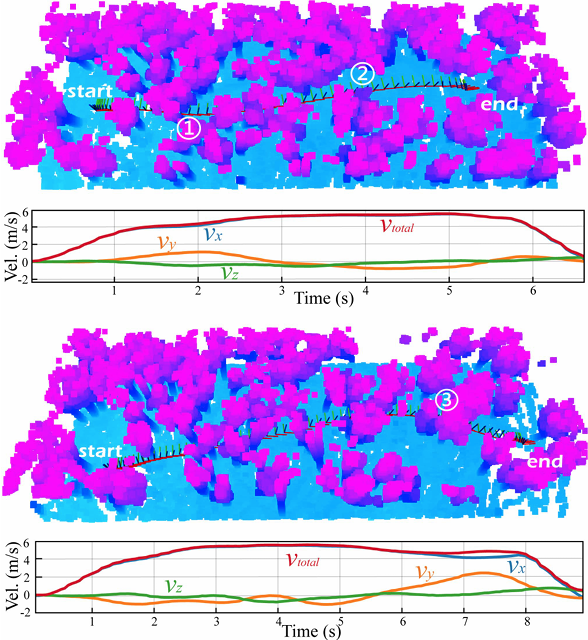
图片来源:Junjie Lu et al.,“You Only Plan Once: A Learning-Based One-Stage Planner With Guidance Learning,”IEEE Robotics and Automation Letters,2024.
05 SU17复现
阿木实验室SU17科研无人机,已基于论文与开源代码完成了 YOPO算法的复现,并进行了初步测试验证,YOPO算法展现出了优秀的响应速度和较强的泛化能力。我们将在后续基于SU17推出完整的复现教程,包括训练环境搭建、模型部署与控制器对接,欢迎持续关注!
资源速递
开源代码:
https://github.com/TJU-Aerial-Robotics/YOPO
论文链接:
https://ieeexplore.ieee.org/document/10528860
DOI:10.1109/LRA.2024.3399589_
文章内容仅用于学术交流与技术分享,图文资料版权归原作者及期刊所有,如有侵权请联系删除。
如果您有感兴趣的技术话题,请在留言区告诉我们!关注阿木实验室,更多技术干货不断更新!开发遇到棘手难题可以上阿木官方论坛:
bbs.amovlab.com
有工程师亲自解答10000+无人机开发者和你共同进步!


